
Umiejętność konfiguracji protokołów sieciowych jest nieoceniona. Niemniej jednak prawdziwą wartość stanowi umiejętność ich troubleshootingu gdy coś pójdzie nie tak. Nie oszukujmy się – bez poznania wewnętrznych mechanizmów rządzących działaniem poszczególnych protokołów, błądzimy niczym dzieci we mgle, szukając powodu usterki. Przyjrzyjmy się dziś działaniu maszyny stanowej (ang. state machine) protokołu OSPF. Zapraszamy do materiału wideo na początku tego artykułu oraz do notatek poniżej.
Maszyna stanowa OSPF jest niczym innym jak cyklem stanów, przez które przechodzi protokół w trakcie swojego normalnego działania. Zrozumienie działania poszczególnych stanów oraz okoliczności, w których one występują pozwala nam zatem się bardzo dobrze zorientować w sytuacji. Spójrzmy najpierw jak została ta kwestia ujęta w RFC 2328 z 1998 roku.
Maszyna stanowa OSPFv2 w RFC 2328
Informację w postaci diagramu znajdujemy na stronie 83. oraz 84. dokumentu RFC 2328. Prezentuje się ona następująco:
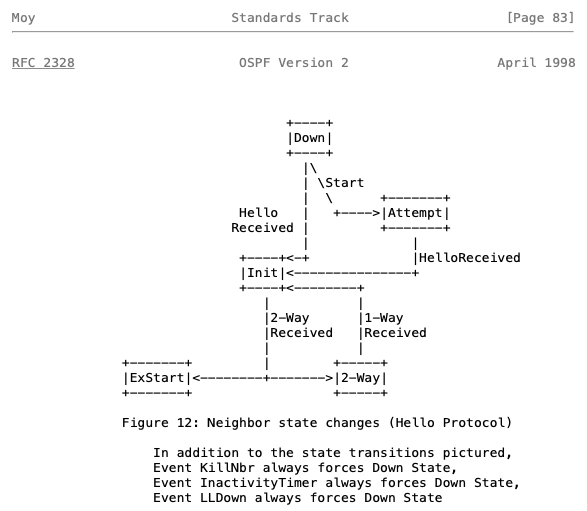
Widzimy tutaj stany związane z wymianą pakietów Hello i nawiązaniem wstępnej relacji sąsiedztwa. Przechodzimy zatem od stanu Down, aż do ExStart, w którym to inicjujemy wymianę tras. Warto zwrócić uwagę w tej części na trzy elementy:

- początkowe stany Down, Attempt oraz Init – a przede wszystkim okoliczności, w których one występują,
- możliwość „cofnięcia się” maszyny stanowej ze stanu 2-Way do Init w przypadku utraty pakietów Hello od neighbora (mamy wtedy notabene do czynienia z komunikacją 1-Way),
- listę niektórych zdarzeń powodujących zmianę stanów.
Kolejna strona RFC precyzuje z kolei dalszą część maszyny stanowej:
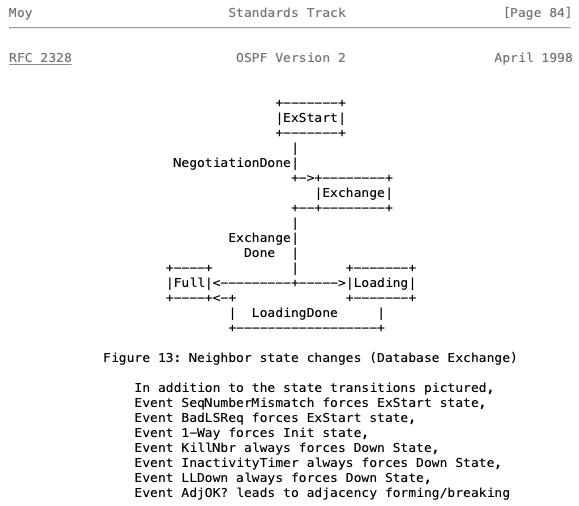
W tej części widzimy dalsze postępowanie procesu, od stanu ExStart, aż do Full. Lista zdarzeń tym razem jest nieco dłuższa.
Tabela poniżej listuje wszystkie stany (z pominięciem Attempt, którego w zasadzie nigdy nie dostrzeżemy w trakcie działania OSPF na danym urządzeniu). Każdy ze stanów jest również pokrótce scharakteryzowany.
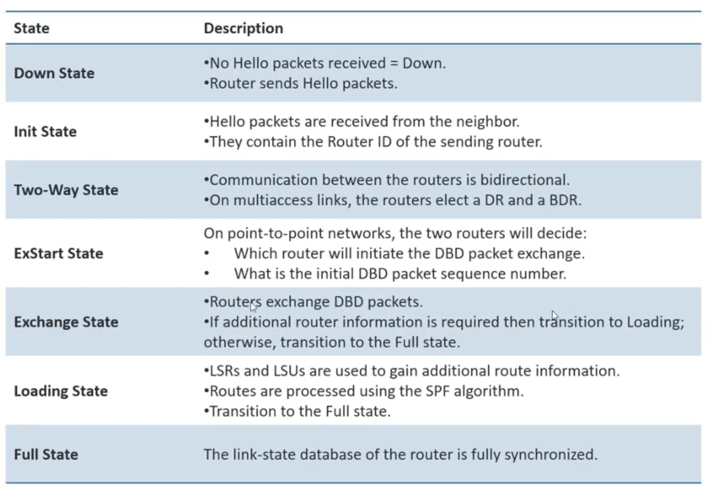
Przyjrzyjmy się teraz bliżej poszczególnym stanom. Na potrzeby naszych rozważań załóżmy, że obserwujemy sytuację z perspektywy R1.
Down & Init
Uruchomienie OSPF powoduje przejście ze stanu Down w stan Init. To w tym stanie zaczynamy wysyłanie pakietów Hello. Celem wysyłania pakietów Hello jest wykrycie innych sąsiadów (neighborów) na danym łączu.

Jeżeli sąsiadujący z nami router otrzyma nasz pakiet Hello (i wszystkie atrybuty, które muszą być zgodne będą… zgodne) to doda on nas do swojej listy sąsiadów (neighbor list).

Kluczowy jest tu fakt, że każdy pakiet Hello zawiera listę sąsiadów danego routera.
2-Way
Gdy otrzymamy od R2 „zwrotny” pakiet Hello, powinien on zawierać nasz własny router-ID na liście sąsiadów. Dodajemy zatem R2 na naszą własną listę sąsiadów i przechodzimy do stanu 2-Way.

Gratulacje! Nawiązaliśmy dwukierunkową relację sąsiedztwa. Jest to dobry moment, aby zwrócić uwagę na to, że istnieje sytuacja, w której maszyna stanowa zatrzyma się na tym stanie (2-Way) i nie pójdzie dalej (w związku z czym z sąsiadem nie wymienimy tras).
Sytuacja taka ma miejsce gdy łączymy nasze routery w rozgłoszeniowym segmencie sieci (takim jak sieci Ethernet łączone np. przełącznikami). Przy pięciu routerach będziemy już mieli do czynienia z dużą ilością pełnych stanów zbieżności (dokładnie n(n-1)/2, gdzie n jest ilością routerów), które musielibyśmy nawiązać. Zmiana bądź strata trasy na jednym z tych routerów wyzwalałaby całą falę aktualizacji, które pochłaniałyby dość sporo przepustowości naszej sieci.

Rozwiązaniem tego problemu jest elekcja routerów DR oraz BDR. Jest to temat wykraczający poza ten materiał, ale pokrótce wspomnę, że sam proces elekcji DR i BDR oparty jest o system priorytetów. Najwyższy priorytet wygrywa, a brane są pod uwagę po kolei: statycznie konfigurowany priorytet (domyślna wartość 1), a następnie najwyższy router-ID.
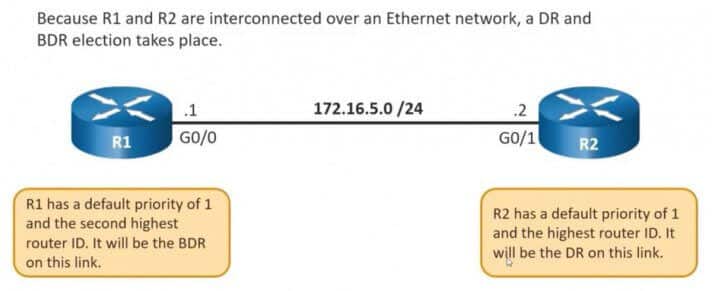
Routery DR oraz BDR nawiążą ze wszystkimi innymi routerami w segmencie Ethernet pełny stan zbieżności (Full) i wymienią z nimi trasy. Natomiast wszystkie pozostałe routery (które nazywamy DROTHER) nawiążą między sobą sąsiedztwo w stanie 2-Way – i na nim się zatrzymają! Będą neighborami – ale nie będą wymieniać tras.
Weź pod uwagę, że jeśli połączysz ze sobą bezpośrednio dwa routery na interfejsach Ethernetowych (tak jak ma to miejsce na przykładzie powyżej) to będzie to z perspektywy OSPF nadal segment broadcastowy i mechanizm elekcji DR oraz BDR będzie miał miejsce. Wynika to bezpośrednio z interfejsów na jakich zestawiliśmy nasze połączenia (w tym przykładzie Gigabit Ethernet). Na interfejsach Serial ta sytuacja by nie wystąpiła.
Aby pozbyć się elekcji DR i BDR na łączu point-to-point zestawionym na interfejsach Ethernet, należy na poziomie tychże interfejsów wydać komendę: ip ospf network point-to-point
ExStart
Czas pójść o krok dalej. Mamy nawiązaną relację sąsiedztwa. Wszystkie routery na połączeniach point-to-point oraz routery DR i BDR w segmentach broadcastowych przechodzą teraz do kolejnego stanu – ExStart. Jest to nic innego jak start procesu synchronizacji LSDB (link state database) pomiędzy routerami.
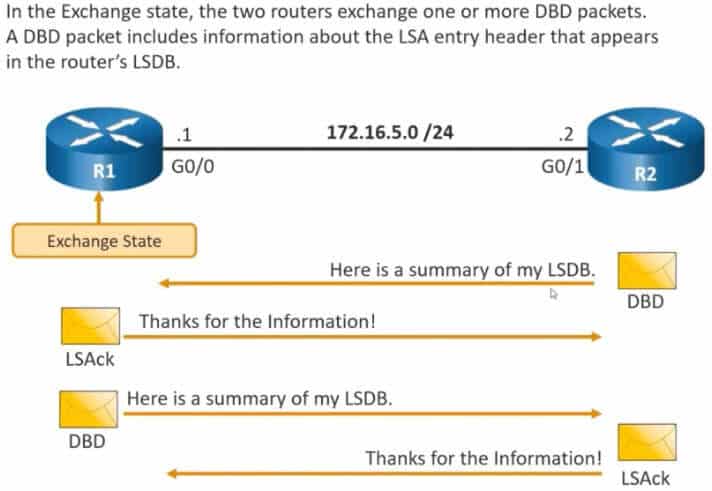
Warto zwrócić uwagę, że proces synchronizacji zaczyna router z najwyższym router-ID. To on jako pierwszy wyśle swoje DBD – czyli Database Descriptor. DBD jest swego rodzaju streszczeniem danych zawartych w LSDB (chcemy zaoszczędzić na przepustowości – po co wysyłać wszystkie szczegółowe trasy skoro sąsiad część z nich może już mieć?).

Exchange
Kolejny stan to Exchange. Tutaj kontynuujemy opisaną wcześniej wymianę pakietów DBD – tak długo aż oba routery nie prześlą deskryptorów dla całej zawartości swoich LSDB.
Loading & Full
Po zakończeniu wymiany DBD przechodzimy do stanu Loading. Nasz router R1 sprawdza informacje zawarte w DBD otrzymanych od R2 i porównuje ich zawartość ze swoją bazą LSDB. W rezultacie takiego porównania R1 będzie w stanie stwierdzić jakich prefiksów mu brakuje (innymi słowy o jakich nowych sieciach wie R2).
Zaczyna się teraz wymiana pakietów LSR (Link State Request) oraz LSU (Link State Updates). Requesty są prośbami o wysłanie szczegółów dotyczących nowych dla R1 prefiksów. R2 odpowiada za pomocą LSU, które mogą zawierać jeden lub więcej pakietów LSA (Link State Advertisement). Każdy LSA jest szczegółowym rekordem dotyczącym konkretnej trasy. No i w końcu – każdy nie każdy LSU musi zostać potwierdzony za pomocą LSAck (Link State Acknowledgement) – tutaj odsyłam pod artykuł do pouczającego komentarza autorstwa Macieja.
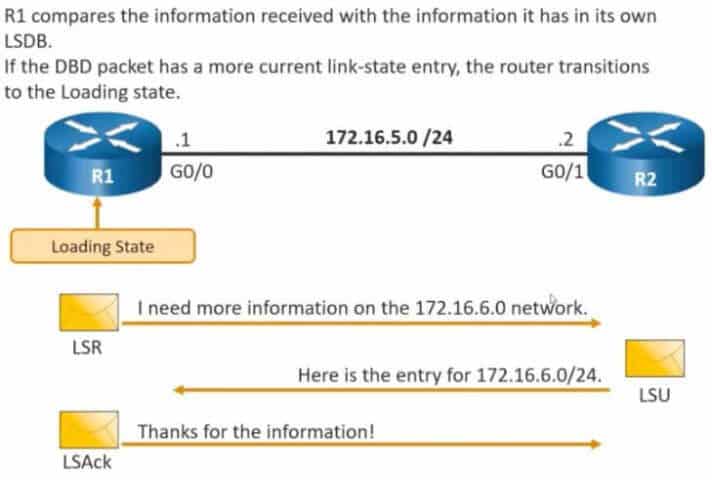
Gdy wszystkie informacje na temat tras zostaną uzupełnione, routery dochodzą do stanu, w których ich LSDB są w pełni zsynchronizowane. Osiągnęliśmy stan Full. I dokładnie o to nam w OSPF chodzi 🙂
Ciąg dalszy
W protokole OSPF kluczowa jest baza LSDB. Warto wiedzieć do czego jest ona nam potrzebna. Przeczytasz o tym w naszym darmowym NSSletterze – mailingu dla sieciowców głodnych wiedzy.
Dołączając uzyskasz dostęp również do archiwum – tematykę tego artykułu rozszerzyliśmy w NSSletterze 23. Rozwiń swoją wiedzę już teraz i zapisz się używając formularza poniżej.
LSAck potwierdza otrzymanie LSA, nie samego LSU. Potwierdzenie jest potrzebne żeby wyrzucić LSA z listy retransmisji ;).
Taka ciekawostka, nie każde LSA musi zostać potwierdzony przez LSAck (explicit ack), kopia otrzymanego LSA w otrzymanym LSU od sąsiada również może posłużyć jako potwierdzenie (implicit ack).
Pięknie dziękuję za wychwycenie błędu i dorzucenie kilku ciekawych informacji 🙂 Faux pas w artykule poprawione 🙂
Heh, to raczej nie jest faux pas, gdyż rzadko kto zwraca uwagę na same LSAck, a co dopiero na piggybacking LSU.
Generalnie jestem w stanie wymyślić tylko 1 scenariusz gdzie ten mechanizm jest używany zgodnie z założeniem:
Pewno można by pokusić się o próbę podciągnięcia pewnych race conditions dla sytuacji \”LSA has been flooded back out receiving interface\”, może gdy topologią to pierścień.
❤️
Ekstra artykuł, dużo rozjaśnił. Dzięki Damian!
Dzięki Bruno 🙂
Ciekawy art.
Dodatkowo, mam kilka pytań odnośnie samego protokołu OSPF.
1. Do czego jest nam potrzebna area 0 (tzw. backbone area) ?
2. Dlaczego potrzebujemy LSDB (czy komunikaty LSA muszą być umieszczane w bazie LSDB) ?
3. Jakie są różne sposoby zmniejszenia liczby LSA w danym obszarze czy też w danej instancji OSPF ?
4. Jakie narzędzia/metody konfiguracji/best practices są dostępne w ramach OSPF, aby zwiększyć jego stabilność oraz mieć mniej obliczeń SPF ?