
BGP to znacznie więcej niż ciekawa historia powstania i odmienne podejście do routingu. To co powinno zainteresować nas sieciowców najbardziej to implementacja techniczna tego protokołu i mechanika jego działania. A jest czemu się przyjrzeć, bo BGP robi wiele rzeczy zupełnie inaczej niż protokoły typu OSPF i EIGRP. W tym materiale porozmawiamy o teoretycznych podstawach działania BGP. Zapraszam!
Po lekturze poprzedniego artykułu powinieneś mieć dobre zrozumienie miejsca jakie BGP zajmuje w kanonie protokołów routingu. Omówiliśmy tam m.in. skąd wynika potrzeba istnienia BGP, czym są systemy autonomiczne, jak kategoryzujemy i klasyfikujemy protokoły routingu i jak się w to wszystko wpasowuje BGP. Zanim zagłębimy się w techniczne zawiłości przyjrzyjmy się raz jeszcze systemom autonomicznym i rozszerzmy naszą wiedzę o nich.
Systemy autonomiczne, runda druga
Border Gateway Protocol został zdefiniowany w RFC 1654 w 1994 roku. Jego działanie od samego początku opierało się o pojęcie systemów autonomicznych. Dla przypomnienia, system autonomiczny to nic innego jak zbiór routerów będących pod kontrolą pojedynczej organizacji. A o jakich organizacja mowa? Najczęściej są to dostawcy usług internetowych, ale nic nie stoi na przeszkodzie aby dowolna firma posiadała swój własny numer AS (ASN).
We wstępnej implementacji BGP na numerowanie systemów autonomicznych przeznaczono zaledwie 16 bitów co pozwoliło nam na adresację 65,535 ASów. Systemy autonomiczne 64512 – 65535 zostały wydzielone jako prywatne. Idea prywatnych ASNów jest bardzo zbliżona do idea prywatnych podsieci (np 10.0.0.0/8).
Dla przykładu dana firma może implementować w swojej sieci jedynie adresację prywatną i nie przejmować się wykupem routowalnego w Internecie adresu publicznego. Adres ten firma może niejako dzierżawić od dostawcy usług internetowych za pośrednictwem którego firma łączy się “na zewnątrz”.
Analogiczna sytuacja może mieć miejsce w przypadku BGP. Numer systemu autonomicznego jest wymagany do działania BGP, zatem nasza przykładowa firma może użyć prywatny ASN na potrzeby uruchomienia BGP między swoją siecią a siecią ISP. Z perspektywy świata zewnętrznego sieć naszej firmy będzie widoczna jako część systemu autonomicznego naszego dostawcy usług internetowych.
Podobnie jak w przypadku adresów IPv4 tak i w przypadku numerów systemów autonomicznych szybko się okazało, że jest ich za mało. W 2007 roku RFC 4893 rozszerzył pole przechowywujące numer AS do 32 bitów. Pozwoliło to zwiększyć zakres dostępnych ASN z 65535 do 4294967295. Wspomiane wcześniej systemy 64512 – 65535 nadal pozostały prywatne i dorzucono drugi zakres prywatnych ASNów w zakresie 4200000000 – 4294967294.
Rola IANA w zarządzaniu ASNami
Publiczne numery systemów autonomicznych są centralnie zarządzane i przypisywane przez organizację IANA. Niezwykle istotne jest aby każda organizacja używała jedynie:
- publicznego ASN przypisanego przez IANA lub
- publicznego ASN przypisanego przez ISP (ISP mogą posiadać całe bloki publicznych numerów systemów autonomicznych, które następnie mogą dzierżawić swoim klientom) lub
- prywatnego ASN z wcześniej podanych zakresów.
Podebranie publicznego ASN od innej firmy bez zezwolenia mogłoby doprowadzić do poważnych problemów, zarówno natury prawnej jak i technicznej (mogłoby to spowodować np. blackholing ruchu sieciowego).
Wiemy już zatem jak istotna jest rola IANA w zarządzaniu ASNami. Co jednak zrobić aby uzyskać publiczny ASN? Spełnić należy minimum dwa warunki:
- organizacja musi posiadać zakres publicznych adresów IP,
- organizacja musi mieć więcej niż jedno łącze do Internetu (w przypadku pojedynczego połączenia uruchamianie BGP nie ma sensu, zostało to wytłumaczone w pierwszym artykule we fragmencie dotyczącym sposobów na podłączenie sieci firmowej do ISP).
Mając już za sobą nieco więcej szczegółów dotyczących systemów autonomicznych, przejdźmy do innych składowych protokołu BGP.
Atrybuty scieżki (path attributes)
Z pierwszego artykułu dowiedzieliśmy się, że BGP używa bardzo złożonej metryki. Nie mamy tu do czynienia z pojęciem kosztu tak jak w przypadku IGP gdzie jest to pojedyncza liczba. BGP zamiast tego z każdym prefiksem w tablicy routingu asocjuje zestaw tzw. atrybutów ścieżki (path attributes – PA). Każdy taki atrybut opisuje inny aspekt danego prefiksu co pozwala na słynną już granularność w definiowaniu polityki routingu w BGP.
Żeby nie było za prosto to atrybuty ścieżki dzielimy na cztery kategorie:
- well-known mandatory – są to ustandaryzowane atrybuty, które muszą być obecne w każdej implementacji protokołu BGP. Oznacza to, że każdy producent sprzętu sieciowego musi nie tylko rozpoznawać te atrybuty, ale również uwzględniać je podczas rozgłaszania prefiksów,
- well-known discretionary – są to również ustandaryzowane atrybuty, które muszą być rozpoznawane w każdej implementacji BGP. Różnica względem atrybutów mandatory jest taka, że atrybuty discretionary nie muszą być zawierane podczas rozgłaszania prefiksów (są po prostu opcjonalne)
- optional transitive – atrybuty z grupy optional nie muszą być rozpoznawane przez inne implementacje BGP. Możemy je zatem rozumieć jako atrybuty implementowane przez poszczególnych producentów sprzętu sieciowego (vendor-specific). Inne firmy mogą, acz nie muszą rozpoznawać tych atrybutów. Słowo transitive oznacza, że dany atrybut niejako się “przykleja” do rozgłaszanego prefiksu i jest uzwględniany w rozgłoszeniach przechodzących przez kolejne systemy autonomiczne
- optional nontransitive – tutaj mamy do czynienia z analogiczną sytuacją jak powyżej, z jedną tylko różnicą – atrybuty są nontransitive a więc są uwzględniane tylko w pojedynczym rozgłoszeniu danego prefiksu do innego systemu autonomicznego i nie są przekazywane do kolejnych ASów.
Więcej o atrybutach ścieżki powiemy sobie w kolejnym artykule z serii.
Formowanie sąsiedztwa, peering bezpośredni oraz multihop

Kolejną ze szczególnych cech protokołu BGP jest to, że nie używa on pakietów Hello do formowania sąsiedztwa. W przeciwieństwie do popularnych protokołów z grupy IGP (takich jak OSPF czy też EIGRP) sąsiedztwa w BGP muszą być formowane statycznie. Powoduje to, że na każdym routerze, na którym chcemy uruchomić BGP musimy z palca statycznie podać adres IP routera, z którym ma zostać zestawiona relacja sąsiedztwa. Kolejną różnicę w BGP dostrzeżemy na poziomie warstwy 4 modelu OSI, czyli warstwy transportowej. Podczas gdy OSPF i EIGRP używają swoich własnych protokołów transportowych, BGP opiera całe swoje działanie na sprawdzonym TCP. Port docelowy, na którym zachodzi komunikacja to port 179.
Wróćmy jeszcze na chwilę do EIGRP oraz OSPF ponieważ niektóre z cech BGP bardzo dobrze się tłumaczy porównując ze sobą te protokoły. Być może pamiętasz, że w EIGRP jednym z warunków zestawienia sąsiedztwa jest znajdowanie się obu routerów w jednej podsieci. Muszą być one zatem ze sobą bezpośrednio połączone linkiem typu point-to-point, bądź też oba muszą się znajdować w tym samym segmencie warstwy drugiej. Innymi słowy oba te routery muszą być w odległości pojedynczego skoku od siebie.
Teoretycznie OSPF rządzi się tymi samymi zasadami, aczkolwiek tam mamy do czynienia z wyjątkiem w postaci virtual-linków… ale to już temat na osobny film. Co zatem jest takiego szczególnego w BGP? Ano to, że w tym przypadku sąsiedztwo może być zestawiane nawet w sytuacji gdy dwa routery nie są ze sobą bezpośrednio połączone. Na samym początku może się to czasem wydawać mało intuicyjne, ale cóż, tak po prostu działa BGP.
W przypadku BGP mamy zatem rodzaje zbieżności, czy też dwa rodzaje peeringów. Pierwszy z nich to dobrze Ci znany choćby z EIGRP peering bezpośredni – czyli tak zwany BGP Direct. Natomiast drugi, ten bardziej szczególny to peering niebezpośredni – czyli tak zwany BGP Multihop.
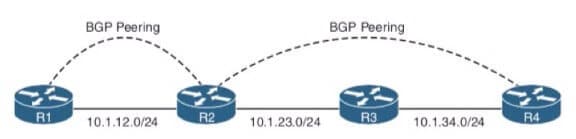
I teraz uwaga, kluczowa sprawa – w przypadku gdy mamy do czynienia z peeringiem Multihop musimy zapewnić podstawową łączność na poziomie warstwy trzeciej pomiędzy routerami, które mają ze sobą zestawić relację sąsiedztwa. W końcu komunikacja BGP oparta na protokole TCP rządzi się takimi samymi prawami jak każda inna zwykła aplikacja. Charakterystyka ta powoduje, że zawsze (niejako “pod” BGP) mamy do czynienia z jakimś innym protokołem routingu z grupy protokołów IGP lub też z routingiem opartym o trasy statyczne.
Dwa typy sesji BGP – iBGP i eBGP
Kolejną rzeczą, którą poruszymy w tym materiale są dwa typy sesji z jakimi mamy do czynienia w BGP. Są to odpowiednio EBGP, co jest skrótem od External BGP oraz IBGP co z kolei rozwijamy jako Internal BGP. Jaka jest różnica między nimi? Jak już być może się domyślasz chodzi tu o systemy autonomiczne omówione w poprzednim materiale. Mając do czynienia z peeringiem BGP między dwoma routerami znajdującymi się w różnych ASach mówimy o sesji EBGP. I odwrotnie – gdy peering BGP zachodzi między dwoma routerami w tym samym systemie autonomicznym to mamy do czynienia z IBGP.
Te dwa typy sesji odróznia ponadto ich domyślny dystans administracyjny. Jest to odpowiednio 20 w przypadku EBGP oraz aż 200 w przypadku IBGP. Widzimy zatem, że spośród wszystkich znanych nam protokołów routingu, trasy nauczone z EBGP będą w czołówce najbardziej preferowanych, podczas gdy te nauczone z IBGP będą preferowane najmniej.
Komunikaty BGP
Przedostatnią kwestią na naszej agendzie są komunikaty BGP. To wprost niewyobrażalne, że protokoł tak potężny jak BGP opiera swoje działanie na w gruncie rzeczy dość prostych mechanizmach. Nie inaczej jest w przypadku komunikatów, które protokół ten używa, mamy ich albowiem zaledwie cztery i są to kolejno:
- OPEN
- UPDATE
- NOTIFICATION
- KEEPALIVE
Przyjrzyjmy się pokrótce bliżej każdemu z nich.
OPEN
Komunikat ten używany jest do zestawienia sąsiedztwa w BGP. Obie strony biorą udział w negocjacji parametrów połączenia zanim zostanie zestawiony między nimi peering. Komunikat OPEN zawiera kluczowe informacje takie jak między innymi numer wersji protokołu BGP, numer systemu autonomicznego routera, z którego komunikat OPEN został nadany, warość licznika Hold Time, o którym za chwilę oraz identyfikator BGP czy też innymi słowy Router-ID (RID) nadawcy.
Licznikowi Hold Time przyjrzyjmy się bliżej podczas omawiania maszyny stanowej protokołu BGP, jednakże w tym miejscu warto wspomnieć, że domyślna wartość tego licznika może się różnić w zależności od implementacji i w przypadku routerów Cisco jest to aż 180 sekund.
Identyfikator BGP, czy też Router-ID to nic innego jak unikalny numer zapisywany w formie adresu IP, który w sposób jednoznaczny identyfikuje dany router. Jest to swego rodzaju wizytówka, którą się przedstawia urządzenie. Adres ten może być wybrany dynamicznie bądź też ustawiony statycznie przez administratora. Nie będziemy w tym materiale wnikali głębiej w zasady jakimi się kieruje router podczas dynamicznego wyboru swojego identyfikatora ponieważ proces ten się różni w zależności od tego z jakim systemem operacyjnym mamy do czynienia.
KEEPALIVE
Drugi komunikat w naszym portfolio to nic innego jak mechanim mający za zadanie wykryć czy sąsiad danego routera ma się dobrze. Jest to swego rodzaju komunikat “Podejdź no do płota”. Komunikaty te są wysyłane w interwale czasowym wynoszącym 1/3 licznika Hold Time. Skoro na routerach Cisco Hold Time wynosi 180 sekund to nietrudno się domyślić, że komunikaty KEEPALIVE są wysyłane co 60 sekund. Nasz sąsiad ma więc aż minutę aby podejść do płota. A co się stanie gdy nie podejdzie? Cierpliwości, o maszynie stanowej już za chwilę.
UPDATE
Trzeci komunikat BGP używany jest przede wszystkim do informowania Kargula… sąsiada o nowych trasach. Ale nie tylko! Można go również użyć w odwrotnej sytuacji gdy chcemy poinformować sąsiada o tym , które trasy są już nieaktualne i powinny zostać usunięte z tablicy routingu. Nowe trasy wewnątrz komunikatu UPDATE przekazywane są w jednostkach nazywanych NLRI czyli Network Layer Reachability Information. A co znajdziemy w NLRI? Przede wszystkim prefix, którego on dotyczy (czyli podsieć i maskę) oraz powiązane z tym prefixem atrybuty ścieżki, o których powiedzieliśmy sobie nieco wcześniej. Warto również wiedzieć, że otrzymanie komunikatu UPDATE jest traktowane tak, jakby doszedł komunikat KEEPALIVE co przyczynia się do ograniczenia niepotrzebnego ruchu.
NOTIFICATION
I tym samym dochodzimy do ostatniego, czwartego komunikatu BGP. Jest on wysyłany za każdym razem gdy zostanie wykryty jakiś błąd i według mnie byłoby znacznie lepiej gdyby komunikat ten nazywał się po prostu ERROR. A o jakich błędach tu mowa? Może to być na przykład upłynięcie czasu odmierzanego przez Hold Timer, zresetowanie sesji BGP czy też zmiana któregoś z parametrów naszego sąsiada takiego jak chociażby omówiony wcześniej Router-ID.
Maszyna stanowa BGP
I tym oto sposobem dochodzimy do Creme de la Creme tego materiału czyli maszyny stanowej BGP. Wiemy już, że relacja sąsiedztwa (czy też sesja BGP) jest zestawiana przy pomocy protokołu TCP pomiędzy dwoma routerami, które notabene nazywami peerami. Dlatego też mamy zresztą do czynienia z peeringiem. BGP śledzi status wspomnianej relacji sąsiedztwa i opisuje go przy pomocy sześciu stanów, w których może się znaleźć nasza sesja BGP. Stany te to kolejno:
- Idle
- Connect
- Active
- OpenSent
- OpenConfirm
- Established
Proces możliwych przejść przez te stany nazywamy skończoną maszyną stanową, z angielskiego FSM czyli Finite State Machine. Wygląda ona następująco:
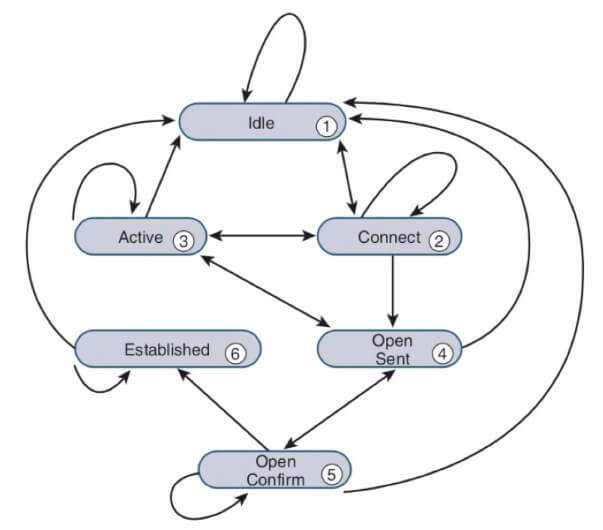
Maszyna stanowa to dość długi temat, którego zrozumienie jest kluczowe zwłaszcza podczas troubleshootingu BGP.
Ufff, to by było na tyle w tym materiale! Jeżeli okazał on się dla Ciebie przydatny to mam do Ciebie prośbę – zasubskrybuj nasz kanał na YouTubie. Twoja subskrypcja będzie dla nas świetną motywacją do tworzenia kolejnych materiałów takich jak ten. Z góry Ci dziękuję!
Przeczytałem tekst i mi się podoba. Vloga przeleciałem na szybko i zdecydowanie wolę w takich tematach czytać tekst. Ale może ja za stary jestem i nie nadążam za modą 🙂 Tak czy inaczej dobra robota. Precyzując jeszcze, to nie IANA przydziela ASNy, od tego jest RIR. Czekam na kolejne części 🙂
Dlatego jeżeli ktoś nie lubi słuchać j woli czytać to przygotowaliśmy transkrypt podcastu do pobrania na stronie odcinka 😉 Dzięki za doprecyzowanie, faktycznie mogłem wprowadzić w błąd tym stwierdzeniem o IANA. To tak dla uporządkowania informacji dodam, że IANA (Internet Assigned Numbers Authority) zarządza zakresami ASN, natomiast przypisują je RIR (Regional Internet Registry). RIR na Europę to RIPE NCC. Pozdrawiam 🙂
Przy omawianiu odległości administracyjnych dla I-BGP i E-BGP wypadałoby dodać, że chodzi o Cisco :). Odległości administracyjne protokołów routingu to jest rzecz totalnie vendor-specific. Nie zapominajcie, że na Cisco świat się nie kończy.
Cenna uwaga, będziemy częściej zaznaczać tego typu niuanse. W tym wypadku (niestety) to przeoczyłem. Dzięki!
Ciekawe jest BGP. Chetnie bym sie zapoznal z dzialaniem tego protokolu z punktu widzenia ISP. Czyli po prostu jak go wykorzystuja dostawcy internetowi. Pozdrawiam i czekam na dalsze odcinki o BGP
ISP może wykorzystywać BGP na potrzeby połączenia swojej sieci z Internetem, z innym ISP, z IX\’em czy również wewnętrznie o czym wspominał Damian nawiązując do prywatnych ASN. Generalnie wszędzie gdzie trzeba w L3 zastosować nadmiarowość, można do tego celu wykorzystać BGP. Np. wykorzystujemy ten protokół również dla redundancji dosyłu IPTV (PIM). Naskrobałem kiedyś taki poradnik dla małych ISP którzy rozważają wdrożenie BGP na styku swojej sieci: https://netmon.pl/index.php/2018/02/09/o-bgp-sieciach-isp/ Jeżeli link jest nieodpowiednią reklamą, to proszę o usunięcie i przepraszam 🙂
Dzieki za link, pomoglo 🙂
Fajny artykuł. Na koniec serii liczę na jakieś ciekawe przypadki \”z życia wzięte\” zachowania BGP lub/i techniki troubleshootingu 😉
Jeśli chodzi o najtrudniejsze zagadnienie z BGP to pamiętam jak się pierwszy raz uczyłem o tym protokole to trudno było mi zrozumieć Split Horizon Rule i powiązaną z nią BGP synchronization rule. Teraz wydaje się to logiczne ale na początku pamiętam jak czytałem definicje po kilka razy nie mogąc zrozumieć o co w tym chodzi 😛
Bardzo ciekawy materiał. Czekam na kolejną część.
A może tak coś o MPLS?
Pozdrawiam